Ever wondered how AI, from creating images to writing text, actually “thinks”? It’s not a monolithic brain, but rather an intricate network built from countless tiny components. To truly grasp AI’s capabilities, we need to understand its fundamental building blocks: tokens.
Think of the human brain. Its astounding ability to process information and generate thoughts comes from billions of individual brain cells, or neurons, each connecting and firing signals in complex patterns.
In much the same way, if an entire AI model is like the vast human brain, then AI tokens are its individual brain cells.
WHY
The answer lies in the fundamental nature of how computers process information, it only understands numbers.
HOW
AI doesn’t just “read” text; it breaks it down into tokens using a tokenizer. Think of a tokenizer as a linguistic surgeon, dissecting raw text into meaningful units.
The exact method varies, but the general process is:
Break Down Text: The tokenizer first splits continuous text into smaller units. This isn’t just splitting by spaces. There are different types of splitting stratgegies used, below table summarizes the pros and cons of each, and looking at it you can guess why the most popular one is Subword tokenization

Subword tokenization (like BPE or WordPiece) is common for large language models. It smartly balances word and character-level approaches. It identifies common characters and sequences, then merges frequent pairs into new, longer subwords. This allows the AI to understand both common words and rare ones by breaking them into familiar subword units (e.g., “unbelievable” becomes [“un”, “believe”, “able”]).
Assign Numerical IDs: Each unique token is then given a unique numerical ID. This ID is the AI’s actual language (e.g., “the” becomes 123).
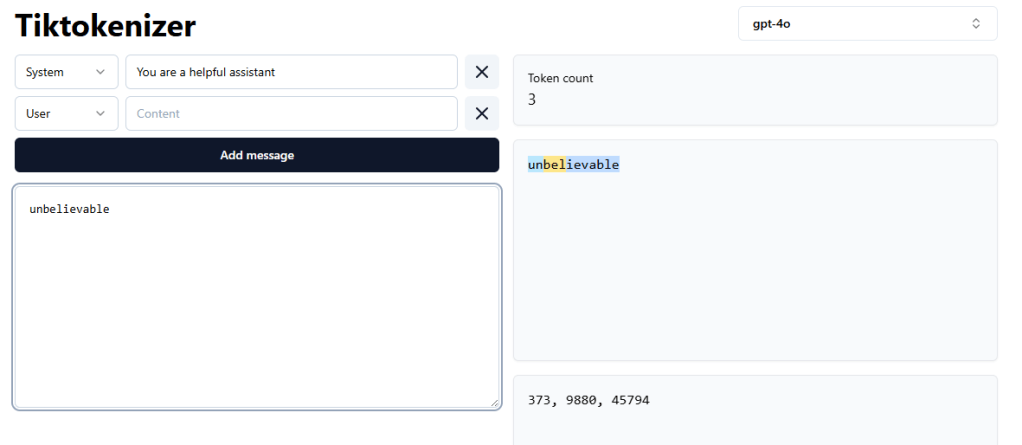
Great way to visualize the token generation is to use tiktok, just kidding, its to use tiktokenizer
If you simply type the word “unbelievable” you can see how one word generates 3 or more tokens.
Tokenization is a crucial step, but it’s part of a much longer journey. Significant processes, starting with data gathering and continuing well beyond tokenization, are necessary before we arrive at a sophisticated LLM like ChatGPT. This intricate pipeline owes much to the insightful, freely available content from Andrej Karpathy on YouTube. More to come.
Now, go fix some bugs!

