augment
verb
/ɔːɡˈmɛnt/
make (something) greater by adding to it.What
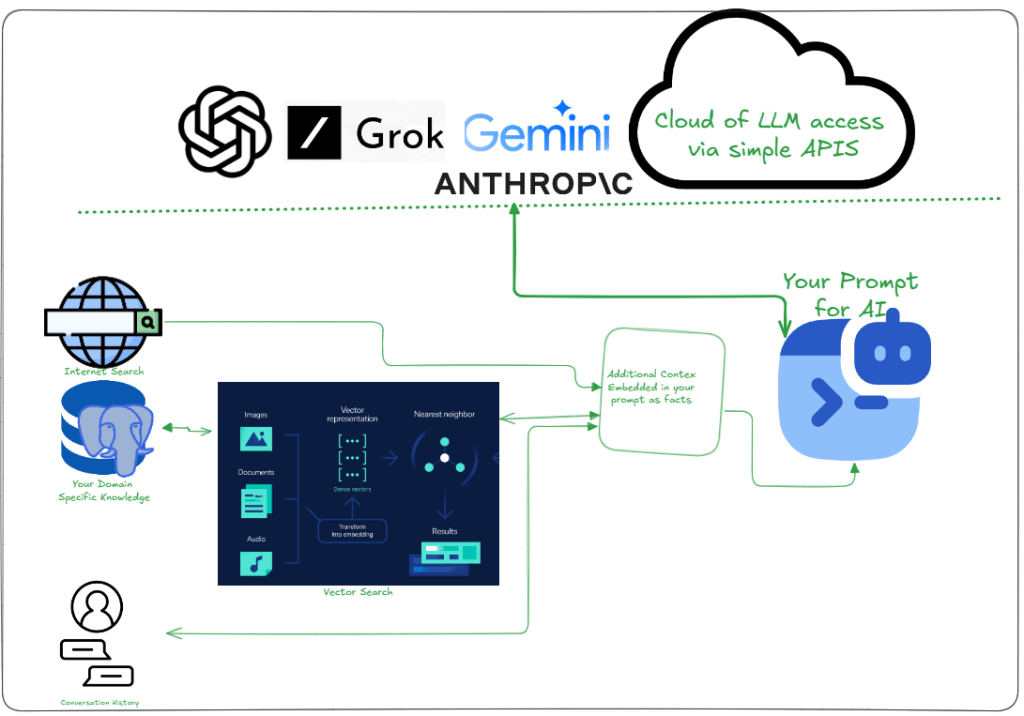
Since “augmenting” implies enhancing or expanding something, it naturally suggests that the LLM — already valuable on its own — serves as the foundation for this improvement. By feeding it additional context, its responses become more accurate, relevant, and informed.
Why
- Outdated Knowledge: Training data is static.
- Domain Limits: Lack specialized expertise.
- Hallucinations: Generate false information.
- Context Gaps: Limited memory for long interactions.
- Real-time Needs: Cannot access live data.
How
- Outdated Knowledge: Implement asynchronous document updates and vector embedding refreshes to maintain current information in the external knowledge base.
- Domain Limits: Curate domain-specific knowledge bases and employ context-aware fusion mechanisms for tailored information integration.
- Hallucinations: Utilize relevancy search with vector representations to retrieve and augment LLM prompts with factual, authoritative information.
- Context Gaps: Apply efficient document retrieval strategies and context management techniques, such as TF-IDF or BM25, to handle large context sizes within model token limits.
- Real-time Needs: Incorporate dynamic information retrieval components that access up-to-date external data sources before LLM generation
This is by no means a comprehensive guide — rather, it’s a straightforward way of documenting my current understanding. For each of these topics, there are countless resources available to explore in greater depth. Hope this gives your learning a fun boost!
Now, go fix some bugs!
